This is quite an interesting one, raising this ticket so I can keep track of what I need to do to get this fixed.
Background
An issue was originally filed seeking advice in my Ecowitt_to_InfluxDB project
I'm also using Python/Flask to receive the POST data from the Ecowitt but I'm having some really weird issues with the request object and the way Flask parses out the request.form data.
Like you, I initially tried to access the POST data with: (
request.form)which worked absolutely fine for my "faked" data submitted using curl but was empty for real data from the Ecowitt. A packet dump shows all the form data is present and correct, just that Flask doesn't seem to access it.
A related issue was found in the Flask/Werkzeug repo
What happens is that in the route handler, request.form is empty depending on how the form request looks in detail. Now sending a POST request using a simple html form works fine as long as it looks like this: ith that request, request.form is filled and the data can be parsed normally. However, the Ecowitt station sends requests that have a different set of header fields, which looks like this:
POST /weather/report HTTP/1.1
HOST: 192.168.178.208
Connection: Close
Content-Type: application/x-www-form-urlencoded
Content-Length:502
PASSKEY=78D8DCE861B2164BAD38A473167ACFD2&stationtype=GW2000A_V2.2.4&runtime=1247&dateutc=2023-06-17+10:3
Sending that request results in an empty request.form. It's also no use to try and use request.get_data() or stuff like that. The method in both requests is POST.
There was initially some suggestion that the missing space in the Content-Length header might be the issue.
However, RFC 7230 states that whitespace around header field values is optional (and "ought to be excluded" from values when parsing).
It wasn't, however possible to repro the behaviour by omitting this space:
Example app (repro.py)
from flask import Flask, request
app = Flask(__name__)
@app.route('/', methods=["POST"])
def hello():
return request.get_data(as_text=True)
app.run(host="0.0.0.0", port=8090, debug=True)
repro attempt
printf "POST / HTTP/1.1\r\nHost:127.0.0.1:8090\r\nContent-Length:15\r\nContent-Type: application/x-www-form-urlencoded\r\n\r\nfoo=bar&sed=zoo" | nc 127.0.0.1 8090
HTTP/1.1 200 OK
Server: Werkzeug/2.3.6 Python/3.10.6
Date: Wed, 21 Jun 2023 13:35:50 GMT
Content-Type: text/html; charset=utf-8
Content-Length: 15
Connection: close
foo=bar&sed=zoo
Failed - the expectation was that we wouldn't get the POST body returned to us (because the application's not supposed to have it).
To dig in further I took a packet capture of my weather station's writes and found the headers were formatted the same way as described in the ticket
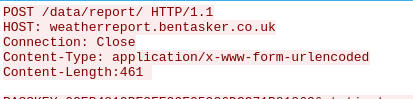
This suggested it should be capable of exhibiting the behaviour described in GH.
Further analysis of the packet capture helped to identify the cause of the issue
Cause
It's present but non-obvious in the screenshot above (and un-noticeable in something like a Github description), but looking at the packet bytes:

The Content-Length header value has a trailing space (20 in hex) before the CRLF.
Again, this is legal under RFC 7230, but allowed a repro to be built (same command as before, but with a space after the content length value)
ben@optimus:~/tmp$ printf "POST / HTTP/1.1\r\nHost:127.0.0.1:8090\r\nContent-Length:15 \r\nContent-Type: application/x-www-form-urlencoded\r\n\r\nfoo=bar&sed=zoo" | nc 127.0.0.1 8090
HTTP/1.1 200 OK
Server: Werkzeug/2.3.6 Python/3.10.6
Date: Wed, 21 Jun 2023 16:11:30 GMT
Content-Type: text/html; charset=utf-8
Content-Length: 0
Connection: close
Repro!
Root Cause
As noted here Flask's debug server is a thin wrapper around Python's http.server.
When http.server receives a request it calls http.client.parse_headers() to parse the request headers.
http.client doesn't perform the header parsing itself, but instead imports Python's email and passes the headers (currently one long string) into email.parser.Parser.parsestr()
Eventually the call chain works down to _parsegen() which calls email.EmailPolicy.header_source_parse().
The function is quite simple:
def header_source_parse(self, sourcelines):
"""+
The name is parsed as everything up to the ':' and returned unmodified.
The value is determined by stripping leading whitespace off the
remainder of the first line, joining all subsequent lines together, and
stripping any trailing carriage return or linefeed characters.
"""
name, value = sourcelines[0].split(':', 1)
value = value.lstrip(' \t') + ''.join(sourcelines[1:])
return (name, value.rstrip('\r\n'))
The important bit is that middle line.
It's stripping any leading whitespace, but not any trailing whitespace.
We can show the effect of this
>>> header_source_parse(["content-length:15 "])
('content-length', '15 ')
The trailing space is left in place, and bubbles back up the callchain back into Flask.
Flask's form data parser looks like this
def start_file_streaming(
self, event: File, total_content_length: int | None
) -> t.IO[bytes]:
content_type = event.headers.get("content-type")
try:
content_length = _plain_int(event.headers["content-length"])
except (KeyError, ValueError):
content_length = 0
container = self.stream_factory(
total_content_length=total_content_length,
filename=event.filename,
content_type=content_type,
content_length=content_length,
)
return container
It calls _plain_int() to convert the content-length header to an integer. This is where the breakage happens.
_plain_int() tests the value against re.compile(r"-?\d+", re.ASCII), which doesn't permit spaces (and why should it?)
When the value doesn't match the regex (because of the trailing space), the content-length value is set to 0 by start_file_streaming(). As a result, the form data then won't be read in, so is not available via request.form and request.get_data().
RFC Conflict
There is a reason why header_source_parse() does not strip trailing whitespace
Email header formatting is governed by RFC 5322 which (arguably) considers trailing spaces to be part of the value. It doesn't make any special dispensation for stripping trailing spaces.
This is incompatible with how the HTTP spec believes header values should be parsed.
Fix
There are two fixes that are needed
- Have Werkzeug strip any trailing whitepace in
_plain_int()(there's also a_plain_float()that should do it too): Werkzeug Pull 2738 - Get a PR into Python to strip the whitespace: Python issue 105973
Activity
22-Jun-23 08:12
assigned to @btasker
22-Jun-23 08:13
changed the description
22-Jun-23 12:01
OK, so having already put the Werkzeug PR in to have Flask mitigate, the next thing to do is to put together a PR for Python itself.
Per the code-owner's instruction, we need to
I think in this case, it actually probably makes sense to write the test-case first and then implement the fix.
22-Jun-23 12:11
Although it could be tested via the HTTP server tests, it probably makes most sense to add to the HTTP Lib tests
There's a doc at writing tests for python
Installing build deps (I already have
build-essentialsetc)Running the existing tests
The result is
22-Jun-23 12:38
I'm out of lunch break, but have implemented the test (
test_header_whitespace_removal).22-Jun-23 18:30
Now I can see why the maintainer of
emailsaid thatBut, I believe I've got an initial implementation.
Some notes:
for header in headers. The HTTP spec allows multiple headers with the same name.__getitem__cannot work with thismessage.get_all()to retrieve all values for the headeremail.raw_items()to retrieve a list of tuples of name + valuemessage.__setitem__sets header and value, but does not overwrite existing headers with the same namemessage.__delitem__deletes all headers with that name__delitem__once before using__setitem__to add the new header(s)This currently takes the following form
Introduced in commit fb8fc15.
I've also added some additional tests:
set-cookieheaders are preserved (Commit 12ec939)The library specific tests pass, running full tests now to double check I've not introduced any wider issues
22-Jun-23 18:49
PR 105994 is up and awaiting review.
23-Jun-23 07:34
One of the maintainers has asked that we go a different route and adjust
email.policy.HTTPso that it's able to form the headers correctly.It'll be more efficient as it removes the need for post-processing.
emailfeels like the wrong place to be doing HTTP specific stuff, but, not my codebase or call :D23-Jun-23 07:44
OK, so need to rebase the branch to remove the following commits
Have synced the branch with the source to make sure we're up to date and rebasing to remove those
Have force pushed to my branch
23-Jun-23 07:48
Oh, that was a mistake, that's pulled other people's commits into the PR need to fix that.
Rebasing again and only picking my own commits... muppet
23-Jun-23 08:13
I've made changes so the Policy classes are able to do this.
If I hardcode the value to
Falsethen my tests pass.However, despite updating the HTTP clone to set this
the test fails.
Best guess, at the moment, is that
http.clientis not actually using the HTTP policy.I'm guessing it's do to with the invocation here
The default value of
_classinhttp.clientisHTTPMessage. Need to look at how the policy is set/specified though.23-Jun-23 11:03
Yeah, it wasn't using HTTP.
Updated to
and shazam!
Unfortunately that seems to have broken some tests
Errors
So we need to add a test for the new attribute - I should have done that anyway.
Looks like we've gained quoting, will have to look at why.
There's a function called
unquoteso might be worth looking at where/why that gets called. Presumably it now isn't when it should be (test isself.assertEqual(response.getheader("Content-type"), "text/html; charset=UTF-8")so the test wants the unquoted version)Either quoted or unquoted is legal under RFC 7231 Sec 3.1.1.1 so we definitely want to restore the original behaviour.
The date handler seems to have changed too.
It looks like
formatdate()handles switching to usingGMTso need to find where that's called and adjust the HTTP policy accordingly.23-Jun-23 11:05
Taken a quick look at
test_email.It's relatively easy to fix - need to update defaults in the tests (which also means we need to update docstrings in the codebase).
The only catch is, the variable name
allow_trailing_whitespaceis quite long, so it fucks with the existing spacing.Rather than respacing everything, I'm going to rename to
rstrip_whitespace(and obviously swap out values)23-Jun-23 12:40
Actually, looking at the input, there are no quotes. Something's adding the quotes, so it's not
unquote()we should be looking for but something that does quoting.I dropped a
print()intofeedparser._parsegen()At that point, the quotes have not been added
The function called by
http.clientisparsestr. At the point that that returnsThe value still isn't quoted
OK, so jumping back into the test itself
gives
The quotes are being added as the result of calling
http.client.getheader().That, in turn calls
Message.get_all(), which in turns callsself.policy.header_fetch_parse(), which then passes it into the relevant header factory (this, incidentally, is where the policies differ - without the change in policy the header would be passed through_sanitizebut that's it).Ultimately it ends up in
parse_content_type_header()(should totally have gone looking forcontent_type...The parameter is then passed into
parse_mime_parameters()which ultimately inserts them into an instance ofMimeParameters()The quoting occurs in
MimeParameters.__str__()That's got no access to the policy.... how the fuck are we going to fix that?
24-Jun-23 06:47
In order to preserve existing behaviour whilst applying the trailing space fix, I adjusted
email.policy.HTTPto be a clone ofCompat32(the class it was using before thehttp.clientchange) rather than ofEmailPolicy. (Commite42e290b57)That change fixes the issue (but currently breaks the email tests).
I've posted a couple of options in the PR to see which the maintainer wants
24-Jun-23 07:06
Turns out I was totally overthinking it.
There's a section in
test_policywhere it specifies where the defaults should be read fromThat's fixed the
emailtests. Have pushed into the PR to check the other tests pass.24-Jun-23 07:12
changed the description
24-Jun-23 07:16
changed the description
24-Jun-23 07:39
Woot, all tests passed.
Awaiting review by the maintainer. I'm guessing they'll probably want me to update the base branch to verify it's still mergeable, but I'll hold off on doing that until asked.
26-Jun-23 09:04
changed the description
13-Aug-23 10:09
Looks like my PR targetted the wrong branch (I went for
main, but turns out there are release specific branches). The maintainer has corrected that in PR 2764) which is now merged.So, my fix will be in 2.3.7 whenever it rolls out
15-Aug-23 09:30
2.3.7 is out: