Issue Type: issue
Status: closed
Reported By: btasker
Assigned To: btasker
Milestone: v0.2
Created: 12-Feb-23 09:57
Labels:
Bug
Fixed/Done
Description
It's taken a bit of fiddling to work out what's going on here.
In the graphs resulting from downsampling, the left most time ranges are quite often at 0
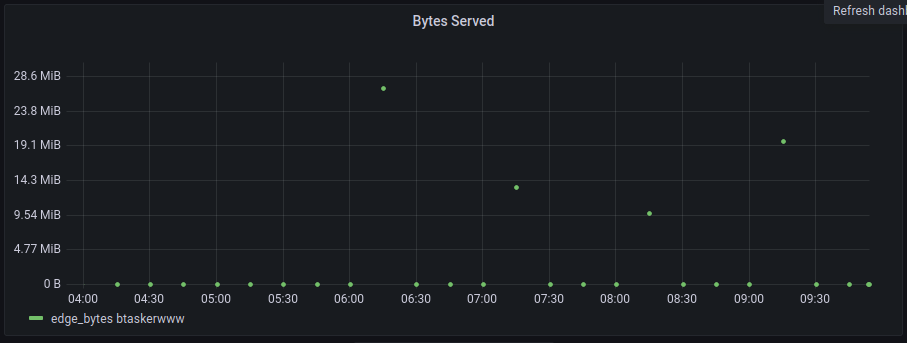
If we compare them to the raw data, we can see there should be a value

A value is present for that time-range in the flux-task downsampled set too.
Activity
12-Feb-23 09:57
assigned to @btasker
12-Feb-23 10:10
I think this is happening because the trailing edge ends up having 0 points in it, and we started writing 0 values in in #20.
So, if a run starts at 45 pas the hour we'll get a query like this:
(I've added field filters to help make it readable and increased to a 4 hr window)
If we run that against the raw data in Chronograf (with a group to collapse to one series), we get a graph like this
In Grafana we still get
The shape of the second half is correct, but there's a value missing in the trailing edge.
If we remove the
group()from chronograf we can see that there are empty windows in thereWhen processing a window, we take the
stopdate - there's data in a window running from 06:00-06:15 so we should see a value of28286756at that time in Grafana, but we don't, we get a 0.If we now update the query to slide our window along 15m
12-Feb-23 10:17
The query is now
If we look at the raw data, we now have the following empty windows
Note that 06:00-06:15 is now empty - in the previous query it had a value, but since we've slid the window it now doesn't.
As a result, the downsampling script will insert a 0, upserting the value that existed from the prior run.
The result is, that since I "fixed" #20 last night, we've been slowly removing history: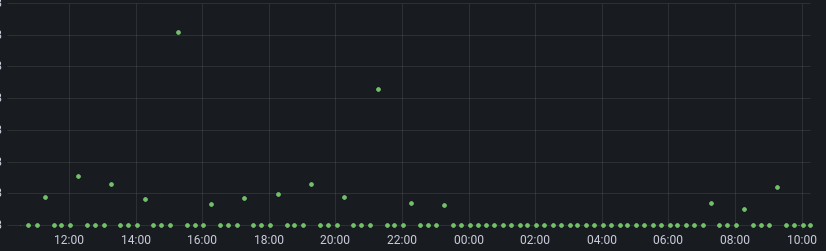
That leaves us with 2 questions:
12-Feb-23 10:18
I don't like it, but one answer is probably to do a comparison on
start/stopand see whether they're in proximity of the window bounds, if they are then we should skip (or maybe skip only if empty).We might be able to avoid needing to do time comparisons by tracking which group keys we've seen - the first table we see for a group should also be the first time window
12-Feb-23 15:55
mentioned in commit b7f7bb187821f080e9cbb6e107f4c5f3d7d3f069
Commit: b7f7bb187821f080e9cbb6e107f4c5f3d7d3f069 Author: B Tasker Date: 2023-02-12T15:52:25.000+00:00Message
fix: prevent empty starting window from blatting existing values utilities/python_influxdb_downsample#23
Flux on InfluxDB 1.8.10 appears to disregard values at the beginning of the range, so if
window(createEmpty: trueis used each group will start with an empty window.This is problematic because we'll fill it with a 0. If the starting window was queried in an earlier iteration (i.e. when it wasn't part of the starting range) whatever value it populated will be upserted to a 0
This commit adds tracking of observed group keys. If it's the first time we've seen a group-key and the table is empty, we'll skip it
12-Feb-23 15:59
The test database currently has the following shape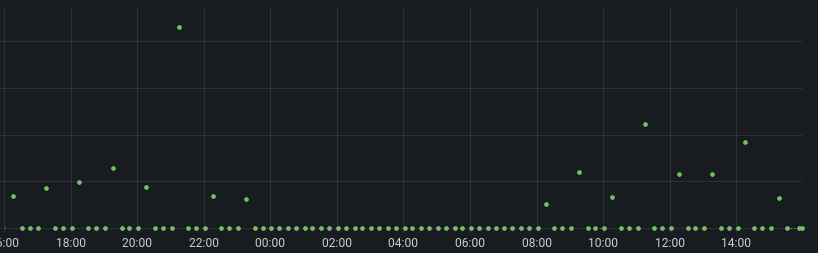 (I extended the range back quickly to re-populate some values)
(I extended the range back quickly to re-populate some values)
What we'll be wanting to see is whether any of those values get squashed in the next run (due in a couple of minutes)
12-Feb-23 16:09
So actually, my query period will have started at 12:00, which had a 0 value anyway - we need to wait for the next run to see whether that 12:15 survives.
12-Feb-23 16:23
That point survived.
I've just given it a run with a day's data, and 16:16 yesterday hasn't been splatted.
So, it looks like this is now working as it should. I'll remove the debug stuff and then close.
12-Feb-23 16:24
mentioned in commit 996cf415c9669a819115f60910c6e441a01a64e6
Commit: 996cf415c9669a819115f60910c6e441a01a64e6 Author: B Tasker Date: 2023-02-12T16:24:11.000+00:00Message
chore: remove debug print (utilities/python_influxdb_downsample#23)