Issue Type: issue
Status: closed
Reported By: btasker
Assigned To: btasker
Milestone: v0.2
Created: 08-May-23 10:28
Labels:
Bug
Fixed/Done
Description
There's a good example in #25 of windows timings being slightly off, leading to duplicated windows
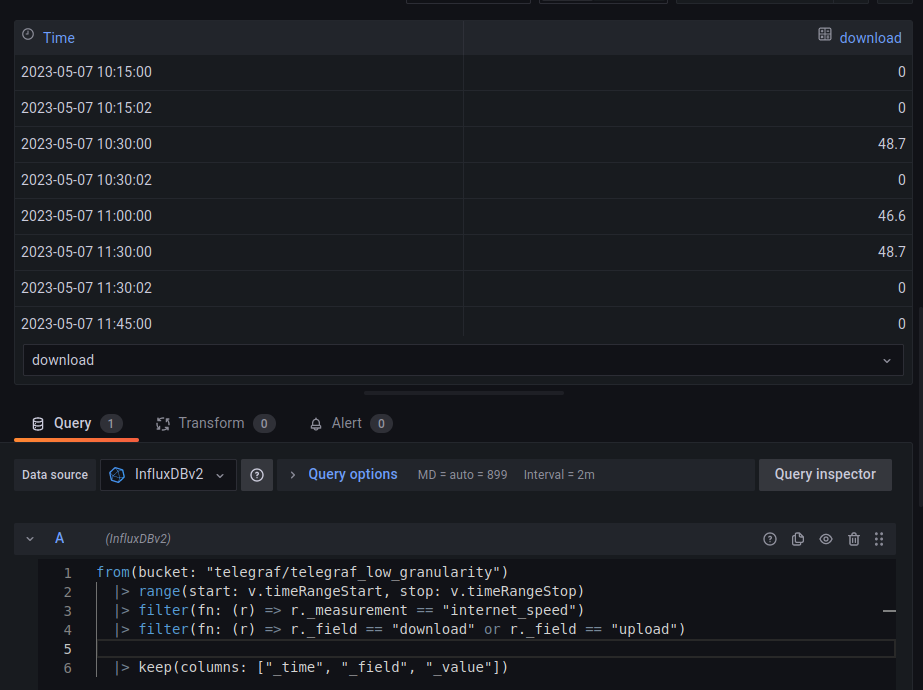
In that screenshot there's a window for 10:15 and another for 10:15:02.
That's happened because, on one run, downsample has started about 2s after the turn of the minute (most likely, the docker image took a while to fire up).
At startup, we calculate the start time that'll be used in queries:
# See if the environment overrides the start time
if ENV_START and len(ENV_START) > 0:
start_time = datetime.datetime.strptime(ENV_START, '%Y-%m-%dT%H:%M:%S').astimezone(tz=datetime.timezone.utc)
else:
# Calculate task start time
# this will be used to help calculate the start time for queries
start_time = datetime.datetime.now(tz=datetime.timezone.utc)
start_time is then used as the stop value in generated queries.
The problem is, if there's more than a second's delay in reaching this calculation, result windows will be slightly offset by that delay (i.e. starting at 00:00:01 instead of 00:00:00).
We should probably include a configuration option which allows this time to be rounded down to a set unit
Activity
08-May-23 10:28
assigned to @btasker
08-May-23 11:06
mentioned in commit adb0ae23b2a14d733fd36f4b4f64c9b92dd90859
Commit: adb0ae23b2a14d733fd36f4b4f64c9b92dd90859 Author: B Tasker Date: 2023-05-08T12:04:26.000+01:00Message
Fix: Round run start time down to a fixed precision (utilities/python_influxdb_downsample#27)
If a run starts a few seconds late, this ensures that the calculated windows will still be bound as if it had started on time, rather than ending a few seconds after the minute.
Introduces a new configuration option:
round_start_time08-May-23 11:09
Commit adb0ae23 introduces a new configuration variable
round_start_timeaccepts an integer value representing a precision in seconds. When calculating query time bounds, times will be rounded down to this precision, so with a value of60a timestamp of11:11:15would be rounded down to the nearest 60 seconds, giving11:11:00.Example:
If rounding isn't desired, the option can be omitted from config, or explicitly set to False
08-May-23 11:27
mentioned in issue #20
08-May-23 11:31
It's worth noting that this new functionality also enables a different use-case: staggered jobs.
Assuming we want an hourly downsample, it's now possible to have cron start a job at (say) 20 past but run as if it had started on the hour:
So, if there were a lot of big hourly jobs, we could potentially split them out to seperate runs (rather than simply running sequentially).